Issue #4
Why Your LLM is Like a Mirror
The secret to building with AI is in realizing that LLMs are like mirrors. Being a better engineer has never been more important. And here's why.
The promise of AI as circulated on the internet is simple: AI can write code, so we no longer need software engineers. Because everyone’s a coder now.
I’m afraid that’s like saying: we built a violin so good that we no longer need violinists. Just as a Stradivarius requires a skilled violist, so do powerful AI tools require skilled engineers to wield them effectively.
Remember, the tool is only as good as the hand that uses it. This has implications in both AI product design and agentic coding. We’ll start with coding, because that’s where the impact is easiest to see, and then extend the principle to product design.
The Prompting Problem
There are two facts about LLMs that are not talked about enough.
- They work on the exact same hardware we’ve had for ages, and thus use the same computational constructs. Thus, we’re using those same primitives to simulate intelligence rather than BUILDING intelligence.
- LLMs themselves do not generate text or content, but merely a probability distribution of them. The decoding step randomly picks from that distribution. Which is why the same prompt can answer “yes” one time and “no” the next.
In short, tools will always be tools. And any tool requires skills and mastery to operate. Just having a powerful engine does not make one a skilled driver.
The Mirror in Action
Since LLMs are computational tools, they don’t magically give results just because we asked nicely. It depends on what we ask for and how. That’s where domain knowledge and engineering skills come in handy. Here’s an example.
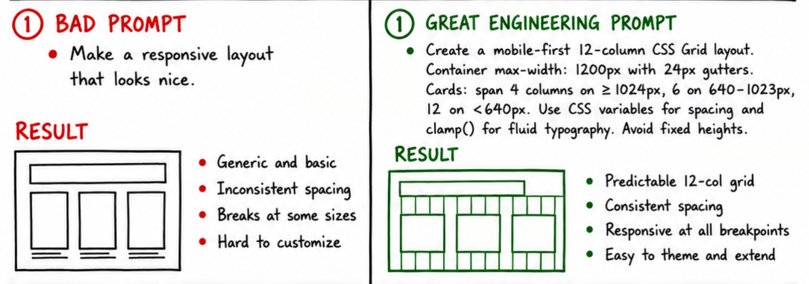
We’re not talking about microservices, or Rust, or intense data science here. We’re talking about something as “simple” as CSS (which is notoriously difficult to master). The prompt to the left is a wish for what’s needed rather than being an instruction or a guideline. The output will be a regression to the mean of whatever’s out there. And that’s the catch.
Mean values are very tricky. If you take a dataset of 2 numbers, namely [2, 4], the mean is 3. But note that the number 3 is NOT in the dataset. Rather, it’s a synthetic value. Similarly, asking the LLM vague requests will yield synthetic outputs that are largely useless, unless those very cases have been tuned by the foundation model companies.
However, being more specific with your requests means your outputs have more chances of matching a real solution rather than a synthetic one no one would use.
Here are two more examples:
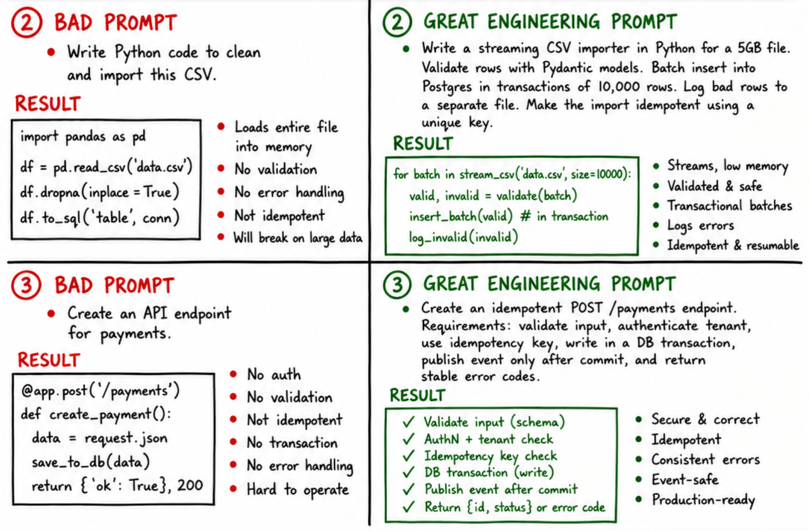
The Implications for Agentic Engineering
This is not merely a matter of using better prompts or adding more context. It’s about being sure of what’s going to be built before we write instructions for it. Or else, we’ll just be the effect of whatever the LLM “decides” that day, rather than causing the effect we want.
The reason LLMs feel like a huge productivity boost for me is because I have the experience to ignore, correct, or otherwise disregard all the junk that it keeps throwing at me. There are times, however, where I have to just sit down and write even a CSS myself, because the LLM is not capable of solving a particular “logical puzzle” behind which is the solution.
Here are some examples of how engineer expertise comes in handy, even with agentic coding:
- Understanding the core technologies, and knowing which ones to use for a problem. By the time you define a problem for an LLM, it is already half-solved.
- Designing the core abstractions so that when LLMs pour tens of thousands of lines of code into them, the foundations still hold.
- Recognizing incorrect approaches, patterns, code smells, which one just feels in their gut but cannot always verbalize. This is the “art” of engineering that’s learnt, but never taught.
- Constantly re-evaluating the current system and recognizing which parts require a re-design or a refactor, and in which manner.
- Translate domain understanding into computational problems, which is then given to the LLM to code.
- And probably a lot more
The Implications for Product Design
As tools like Claude have started producing good-enough frontend design and mocks, many teams skip the whole ideation phase, and accept whatever the LLM produces as the “best” live spec. There is no filter against the outrageously optimistic data dashboards that LLMs love to propose, which would including obtaining data you don’t have, or making claims with confidence that a true statistician would never make.
However, it also gives an enormous opportunity to product teams who understand LLMs better, and use them better than other teams doing a surface-level job. That’s the easiest way to get a competitive advantage in the AI era.
Incidentally, that’s why I also wrote my book, How AI Thinks, which explains the principles of how LLMs work, including creativity, hallucinations, and even reasoning. And it’s done in a very cohesive manner so that you can use the same mental model to understand countless aspects of LLMs. (The book is entirely handwritten, edited, illustrated, and designed using InDesign)
Coming back to our point, the best way to build a better product is to leverage LLMs to accelerate your execution rather than your thinking.
Three rabbit holes people seemed to like
A few related ideas on thinking and engineering took off recently:
Closing Thoughts
Well, LLM’s just another tool to be mastered, and it becomes more valuable when you use it with all the tools you’ve already mastered. Domain knowledge, experience, and engineering skills are more important than ever. The better you are at using the tool, the more powerful it becomes. But if you don’t know how to use it, it can be a liability rather than an asset.
See you in Issue 5!
Get the next issue in your inbox
If you want technical depth, applicability, fun, and profit all at once but have never found them together before, The Invariant is the place to be.
Subscribe today if you have not already.
Free. No spam. Unsubscribe anytime.