Issue #9
Going Beyond RAG
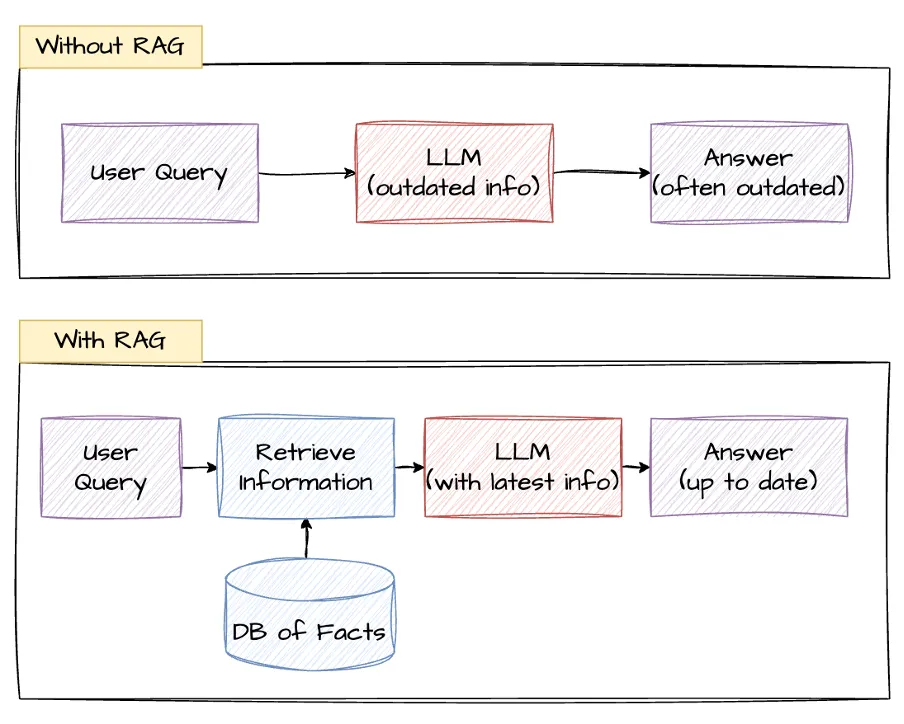
RAG is usually the easiest use case for software engineers to get their feet wet. The core idea is not to rely on the LLM's internal knowledge, which can be outdated. However, most engineers fixate too much on vector and/or keyword search, missing out on deeper agentic patterns. That's what we'll cover in this issue.
RAG is usually the easiest use case for software engineers to get their feet wet. The core idea is not to rely on the LLM’s internal knowledge, which can be outdated. However, most engineers fixate too much on vector and/or keyword search, missing out on deeper agentic patterns. That’s what we’ll cover in this issue.
The Basic RAG
If an LLM was trained in Sep of 2025, then it would not innately have any knowledge of things that came in 2026, for example. This is not only a problem when looking for information, but also in coding agents.
For example, the LLM has seen a version of NextJS code that’s very outdated. So it’s not able to use the latest practices. That’s precisely why a newly initialized NextJS project will have a docs folder, as well as an AGENTS.md instruction to only reference those docs rather than the LLM’s internal knowledge.
Thus, RAG is used to inject context during inference instead of relying on the training data. That’s the fundamental reason for RAG to exist.
However, the name RAG, where the R stands for “Retrieval,” can often lead to a short-sighted view of the architecture’s intent. When we talk about retrieval, the picture that comes immediately to everyone’s mind is databases, or even vector databases. A query would be issued to such a database, and we’d then be able to augment the answer generation with whatever was retrieved. But the fixation on approximate rather than structured retrievals (which has been a theme throughout NLP) is incorrect.
But before we look into an alternative, let’s first understand how we would make RAG agentic.
RAG Made Agentic
One of the first complex data structures that computer engineering/science students learned was the Linked List (I don’t know if that’s still true today). One of the defining factors of a linked list is that you can’t directly index to the nth element. You have to traverse each element until you reach the nth.
A similar concept applies to RAG and information retrieval. When we have a single retrieval stage, as in the first diagram, the only information the LLM can rely on is what it was given.
But in an agentic setting, the LLM uses tool calls to query a knowledge base. For example, it could issue a query and get a few documents as a result, and then decide to issue more queries based on what it has learned, and so on till it has all the details needed for an answer. Thus, the retrieval becomes highly dynamic.
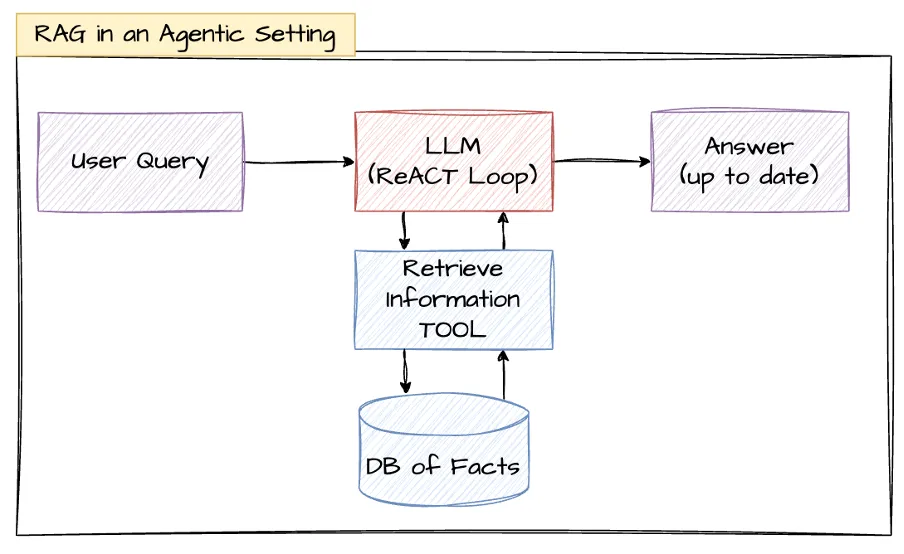
There are a couple of things to notice here:
-
Retrieval has become a tool instead of a static step.
-
The LLM decides when to call the retrieval tool and also supplies the queries (and other filter parameters) for it. It does so through the classic ReACT loop.
-
The LLM can repeatedly call the retrieval tool until it “reasons” that it has assembled all the information.
Because of the agentic loop (ReACT), the LLM can traverse the information space, much like navigating a linked list, to assemble information.
The major switch is retrieval becoming an API rather than a static step. We’ll see why this is important in the next section.
Going Beyond RAG
We saw how retrieval itself became a tool call/API in an agentic setting. But a better generalization is just calling it an API of any kind, rather than labeling it Retrieval.
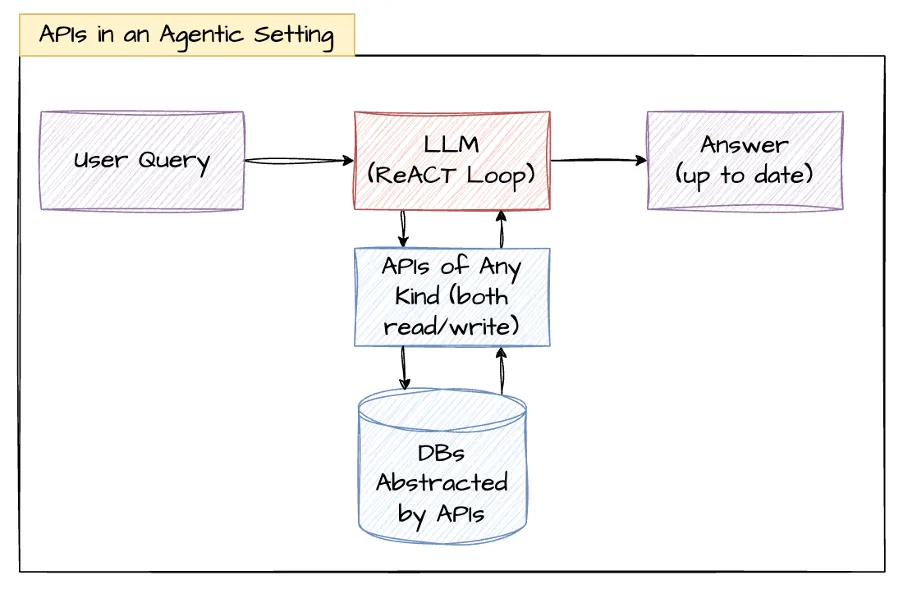
The moment we do this, we realize that we can retrieve more than just documents. And with APIs, it’s not vector search but structured API calls that become powerful.
For example, if you’re creating a support bot, then a simple RAG can only search the knowledge base and suggest generic solutions to the customer. However, a proper API integration can actually help the customer directly with their specific problem, because the bot can operate on the data directly and suggest specific solutions.
These APIs can be both read and write APIs, because in the end, they’re just APIs like any other.
Now, you might see this and immediately think, “oh, this is exactly like MCP!” Actually, no.
MCP standardizes the discovery of APIs and certain authentication/authorization patterns around them, much like a gateway. MCP, however, does not dictate the nature of the APIs themselves. That’s still heavily influenced by what you want your agent to be capable of doing.
With an agentic approach, you can have your agent take on a support ticket for a particular use case, load all resources related to that use case, selectively load logs as needed for those resources, and try to debug the case automatically. That’s the linked-list-like traversal in action. It’s also not directly relevant to MCP, since you might not expose those APIs to the general public.
Also, the power of such an approach is not merely in plugging in an API, but in the harness itself. (I talked about harness engineering in the last issue)
Why?
Because just loading a huge amount of data into the LLM’s context is not a good idea. You might want to store them and have the LLM retrieve or query parts of that data, even if the API returns all that data at once. In short, LLMs should be given data structures that can be queried rather than raw data they must magically infer from.
For example, if you have an API returning a huge JSON, it’d be unwise to dump it into the LLM’s context. Rather, you can retrieve it from the API and temporarily store it, and only add a reference to the LLM’s context. The LLM can then issue “tool calls” (like methods of a data structure) to probe that data without loading all of it into context.
It’s only when we combine great APIs with great LLM harnesses that good products get created. And that’s exactly why we need to go beyond a “RAG”-like approach and view agent architecture as a set of composable patterns. (Much like we do for general systems engineering)
Conclusion
That’s all for Issue 9! I might write a book or create a course on composable patterns in building agents (because that’s how I usually think about it). If you like the idea or have suggestions, just hit reply!
See you in Issue 10!
Get the next issue in your inbox
If you want technical depth, applicability, fun, and profit all at once but have never found them together before, The Invariant is the place to be.
Subscribe today if you have not already.
Free. No spam. Unsubscribe anytime.