Action guide
How LLMs Tokenize Text
Billing and limits disagree with your word count. Rare names and compounds blow up. Tokenization hits cost and quality like a tax you did not see coming.
Get the full guide
Free newsletter unlocks the full guide and subscriber links. Same library working engineers use. No pedigree bingo.
Free. No spam. Unsubscribe anytime.
Why subscribe
Pricing says tokens; intuition says words. Until rare tokens chew budget and quality, you need the tokenizer story before you argue about context limits.
For: Engineers sizing prompts, retrieval, and budget who must explain surprises without sounding like a textbook.
- A concrete mental model of subword behavior
- Why rare strings explode length and hurt outputs
- Better budgeting conversations with finance and PM
- Examples that break naïve splitting
- Rules of thumb for edge cases in prod prompts
- Hooks into latency and cost reasoning
- Links tokenizer quirks to failures users actually see
Subscribe free to unlock the full guide and all future updates.
What you’ll learn
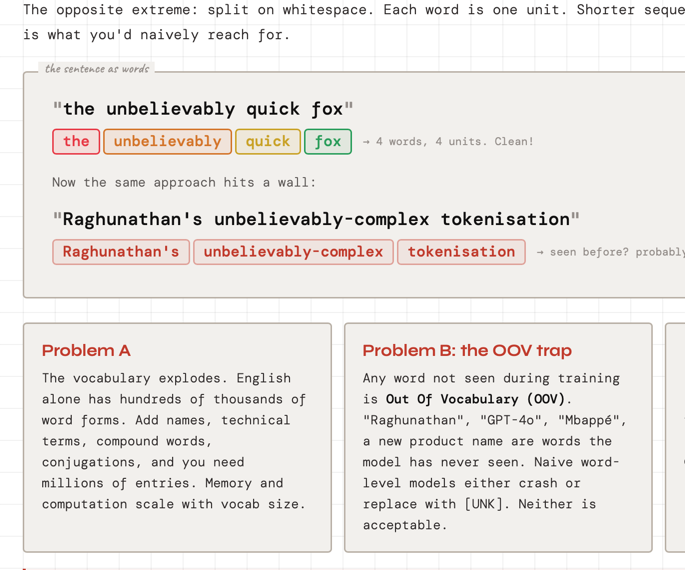
What whitespace / word-level tokenization pretends to solve, where it breaks (hyphenated and possessive words, rarer surface forms), why a growing word list does not scale, and what out-of-vocabulary (OOV) means when the model was never trained on a surface string as a single word.
When you subscribe to the newsletter, you get access to the full online guide alongside course and issue updates.
Explore the other action guides
Each guide kills one sharp problem. You leave with steps you can type, not inspiration quotes.
-
AI Agent Architecture Simplified
'Just add an agent' turned into spaghetti. Here is the ReAct loop you can actually fit in your head. Reason. Act. Observe. Then wire state and tools like a real system.
View guide →
-
Attention: Explained for Engineers
Attention still looks like matrix soup. Here is what Q, K, and V actually do. Why it scales ugly. How to use that when you size context and money.
View guide →
-
Bayes' Theorem Made Simple
Bayes shows up in papers and evals and you freeze. Here is a visual path through priors, likelihoods, and evidence. Plain vocabulary. No stats degree required.
View guide →
-
Build a HackerNews MCP Server From Scratch
From zero to a real MCP server. FastMCP. Real tools. A desktop client path. MCP reads like any other service you ship because it is one.
View guide →
-
Build a Research Agent in LangChain
The smallest LangChain stack for a ReAct research loop. Chat model. Tools. Scratchpad prompt. Executor. Skip drowning in framework trivia.
View guide →
-
DocString and Review Agent in LangGraph
Your agent never knows when to stop. LangGraph with typed state, nodes, edges, and conditional loops. Real design instead of a prayer loop.
View guide →
-
How MCP Works
How host, client, and server really connect in MCP. Integrate and debug like you own the wire, not like a tourist squinting at JSON.
View guide →
-
Prompt LLMs Like a Pro by Context Activation
Longer prompts made outputs worse. Word choice wakes the right slice of training. Stop building walls of text nobody reads.
View guide →
-
Setting Up AI Projects in Python
Your AI repo outgrew the demo script. Env files, pyproject, src layout, and a clean split between HTTP surfaces and agent code.
View guide →
-
Tests That Mean Something
Outputs drift. Your suite shrugs. Here are unit tests that pin behavior you actually care about. Skip the ceremony that only pads ego.
View guide →
-
Understand RAG From First Principles
Naive RAG parrots garbage. Your pile of docs is huge. The model’s window is not. Every extra token hits the invoice. Own the data path or keep paying for lies.
View guide →
-
Write System Prompts for AI Agents Like a Pro
When your system prompt is a novel and the agent still veers: what is already baked into models, and what to add so your instructions carry real signal.
View guide →